24 KiB
![]()
🌍 中文文档
📃 LangChain-Chatchat (formerly Langchain-ChatGLM): A LLM application aims to implement knowledge and search engine based QA based on Langchain and open-source or remote LLM API.
Content
Introduction
🤖️ A Q&A application based on local knowledge base implemented using the idea of langchain. The goal is to build a KBQA(Knowledge based Q&A) solution that is friendly to Chinese scenarios and open source models and can run both offline and online.
💡 Inspried by document.ai and ChatGLM-6B Pull Request , we build a local knowledge base question answering application that can be implemented using an open source model or remote LLM api throughout the process. In the latest version of this project, FastChat is used to access Vicuna, Alpaca, LLaMA, Koala, RWKV and many other models. Relying on langchain , this project supports calling services through the API provided based on FastAPI, or using the WebUI based on Streamlit. ✅ Relying on the open source LLM and Embedding models, this project can realize full-process offline private deployment. At the same time, this project also supports the call of OpenAI GPT API- and Zhipu API, and will continue to expand the access to various models and remote APIs in the future.
⛓️ The implementation principle of this project is shown in the graph below. The main process includes: loading files -> reading text -> text segmentation -> text vectorization -> question vectorization -> matching the top-k most similar to the question vector in the text vector -> The matched text is added to prompt as context and question -> submitted to LLM to generate an answer.
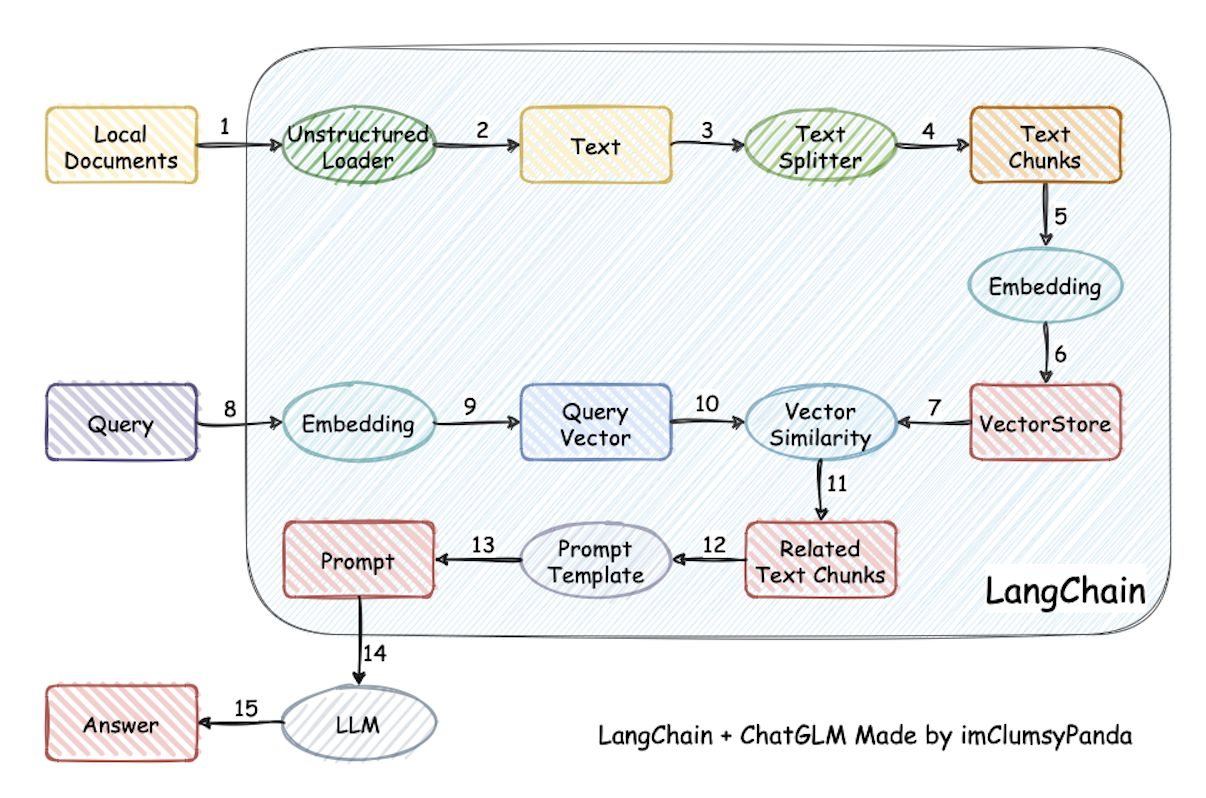
The main process analysis from the aspect of document process:

🚩 The training or fined-tuning are not involved in the project, but still, one always can improve performance by do these.
🌐 AutoDL image is supported, and in v7 the codes are update to v0.2.3.
💻 Run Docker with one command:
docker run -d --gpus all -p 80:8501 registry.cn-beijing.aliyuncs.com/chatchat/chatchat:0.2.0
Environment Minimum Requirements
To run this code smoothly, please configure it according to the following minimum requirements:
- Python version: >= 3.8.5, < 3.11
- Cuda version: >= 11.7, with Python installed.
If you want to run the native model (int4 version) on the GPU without problems, you need at least the following hardware configuration.
- chatglm2-6b & LLaMA-7B Minimum RAM requirement: 7GB Recommended graphics cards: RTX 3060, RTX 2060
- LLaMA-13B Minimum graphics memory requirement: 11GB Recommended cards: RTX 2060 12GB, RTX3060 12GB, RTX3080, RTXA2000
- Qwen-14B-Chat Minimum memory requirement: 13GB Recommended graphics card: RTX 3090
- LLaMA-30B Minimum Memory Requirement: 22GB Recommended Cards: RTX A5000,RTX 3090,RTX 4090,RTX 6000,Tesla V100,RTX Tesla P40
- Minimum memory requirement for LLaMA-65B: 40GB Recommended cards: A100,A40,A6000
If int8 then memory x1.5 fp16 x2.5 requirement. For example: using fp16 to reason about the Qwen-7B-Chat model requires 16GB of video memory.
The above is only an estimate, the actual situation is based on nvidia-smi occupancy.
Change Log
plese refer to version change log
Current Features
- Consistent LLM Service based on FastChat. The project use FastChat to provide the API service of the open source LLM models and access it in the form of OpenAI API interface to improve the loading effect of the LLM model;
- Chain and Agent based on Langchian. Use the existing Chain implementation in langchain to facilitate subsequent access to different types of Chain, and will test Agent access;
- Full fuction API service based on FastAPI. All interfaces can be tested in the docs automatically generated by FastAPI, and all dialogue interfaces support streaming or non-streaming output through parameters. ;
- WebUI service based on Streamlit. With Streamlit, you can choose whether to start WebUI based on API services, add session management, customize session themes and switch, and will support different display of content forms of output in the future;
- Abundant open source LLM and Embedding models. The default LLM model in the project is changed to THUDM/chatglm2-6b, and the default Embedding model is changed to [moka-ai/m3e-base](https:// huggingface.co/moka-ai/m3e-base), the file loading method and the paragraph division method have also been adjusted. In the future, context expansion will be re-implemented and optional settings will be added;
- Multiply vector libraries. The project has expanded support for different types of vector libraries. Including FAISS, Milvus,Milvus,Zilliz,and PGVector;
- Varied Search engines. We provide two search engines now: Bing and DuckDuckGo. DuckDuckGo search does not require configuring an API Key and can be used directly in environments with access to foreign services.
Supported Models
The default LLM model in the project is changed to THUDM/chatglm2-6b, and the default Embedding model is changed to [moka-ai/m3e-base](https:// huggingface.co/moka-ai/m3e-base).
Supported LLM models
The project use FastChat to provide the API service of the open source LLM models, supported models include:
- meta-llama/Llama-2-7b-chat-hf
- Vicuna, Alpaca, LLaMA, Koala
- BlinkDL/RWKV-4-Raven
- camel-ai/CAMEL-13B-Combined-Data
- databricks/dolly-v2-12b
- FreedomIntelligence/phoenix-inst-chat-7b
- h2oai/h2ogpt-gm-oasst1-en-2048-open-llama-7b
- lcw99/polyglot-ko-12.8b-chang-instruct-chat
- lmsys/fastchat-t5-3b-v1.0
- mosaicml/mpt-7b-chat
- Neutralzz/BiLLa-7B-SFT
- nomic-ai/gpt4all-13b-snoozy
- NousResearch/Nous-Hermes-13b
- openaccess-ai-collective/manticore-13b-chat-pyg
- OpenAssistant/oasst-sft-4-pythia-12b-epoch-3.5
- project-baize/baize-v2-7b
- Salesforce/codet5p-6b
- StabilityAI/stablelm-tuned-alpha-7b
- THUDM/chatglm-6b
- THUDM/chatglm2-6b
- tiiuae/falcon-40b
- timdettmers/guanaco-33b-merged
- togethercomputer/RedPajama-INCITE-7B-Chat
- WizardLM/WizardLM-13B-V1.0
- WizardLM/WizardCoder-15B-V1.0
- baichuan-inc/baichuan-7B
- internlm/internlm-chat-7b
- Qwen/Qwen-7B-Chat/Qwen-14B-Chat
- HuggingFaceH4/starchat-beta
- FlagAlpha/Llama2-Chinese-13b-Chat and other models of FlagAlpha
- BAAI/AquilaChat-7B
- all models of OpenOrca
- Spicyboros + airoboros 2.2
- baichuan2-7b/baichuan2-13b
- VMware's OpenLLaMa OpenInstruct
- Any EleutherAI pythia model such as pythia-6.9b(任何 EleutherAI 的 pythia 模型,如 pythia-6.9b)
- Any Peft adapter trained on top of a model above. To activate, must have
peftin the model path. Note: If loading multiple peft models, you can have them share the base model weights by setting the environment variablePEFT_SHARE_BASE_WEIGHTS=truein any model worker.
The above model support list may be updated continuously as FastChat is updated, see FastChat Supported Models List.
In addition to local models, this project also supports direct access to online models such as OpenAI API, Wisdom Spectrum AI, etc. For specific settings, please refer to the configuration information of llm_model_dict in configs/model_configs.py.example.
Online LLM models are currently supported:
The default LLM type used in the project is THUDM/chatglm2-6b, if you need to use other LLM types, please modify llm_model_dict and LLM_MODEL in [configs/model_config.py].
Supported Embedding models
Following models are tested by developers with Embedding class of HuggingFace:
- moka-ai/m3e-small
- moka-ai/m3e-base
- moka-ai/m3e-large
- BAAI/bge-small-zh
- BAAI/bge-base-zh
- BAAI/bge-base-zh-v1.5
- BAAI/bge-large-zh-v1.5
- BAAI/bge-large-zh
- BAAI/bge-large-zh-noinstruct
- sensenova/piccolo-base-zh
- sensenova/piccolo-large-zh
- shibing624/text2vec-base-chinese-sentence
- shibing624/text2vec-base-chinese-paraphrase
- shibing624/text2vec-base-multilingual
- shibing624/text2vec-base-chinese
- shibing624/text2vec-bge-large-chinese
- GanymedeNil/text2vec-large-chinese
- nghuyong/ernie-3.0-nano-zh
- nghuyong/ernie-3.0-base-zh
- sensenova/piccolo-base-zh
- sensenova/piccolo-base-zh
- OpenAI/text-embedding-ada-002
The default Embedding type used in the project is sensenova/piccolo-base-zh, if you want to use other Embedding types, please modify embedding_model_dict and embedding_model_dict and embedding_model_dict in [configs/model_config.py]. MODEL` in [configs/model_config.py].
Build your own Agent tool
Only these Models support Agents
- OpenAI GPT4
- Qwen-14B-Chat
See Custom Agent Instructions for details.
Docker Deployment
🐳 Docker image path: registry.cn-beijing.aliyuncs.com/chatchat/chatchat:0.2.5)
docker run -d --gpus all -p 80:8501 registry.cn-beijing.aliyuncs.com/chatchat/chatchat:0.2.5
- The image size of this version is
33.9GB, usingv0.2.0, withnvidia/cuda:12.1.1-cudnn8-devel-ubuntu22.04as the base image - This version has a built-in
embeddingmodel:m3e-large, built-inchatglm2-6b-32k - This version is designed to facilitate one-click deployment. Please make sure you have installed the NVIDIA driver on your Linux distribution.
- Please note that you do not need to install the CUDA toolkit on the host system, but you need to install the
NVIDIA Driverand theNVIDIA Container Toolkit, please refer to the Installation Guide - It takes a certain amount of time to pull and start for the first time. When starting for the first time, please refer to the figure below to use
docker logs -f <container id>to view the log. - If the startup process is stuck in the
Waiting..step, it is recommended to usedocker exec -it <container id> bashto enter the/logs/directory to view the corresponding stage logs
Development
Environment Prerequisite
The project is tested under Python3.8-python 3.10, CUDA 11.0-CUDA11.7, Windows, macOS of ARM architecture, and Linux platform.
1. Preparing Deployment Environment
Please refer to install.md
2. Downloading model to local disk
For offline deployment only!
If you want to run this project in a local or offline environment, you need to first download the models required for the project to your local computer. Usually the open source LLM and Embedding models can be downloaded from Hugging Face.
Take the LLM model THUDM/chatglm2-6b and Embedding model moka-ai/m3e-base for example:
To download the model, you need to install Git LFS, and then run:
$ git clone https://huggingface.co/THUDM/chatglm2-6b
$ git clone https://huggingface.co/moka-ai/m3e-base
3. Setting Configuration
Copy the model-related parameter configuration template file configs/model_config.py.example and store it under the project path . /configs path and rename it model_config.py.
Copy the service-related parameter configuration template file configs/server_config.py.example and store it under the project path . /configs path and rename it server_config.py.
Before you start executing the Web UI or command line interactions, check that each of the items in configs/model_config.py and configs/server_config.py The model parameters are designed to meet the requirements:
- Please make sure that the local storage path of the downloaded LLM model is written in the
local_model_pathattribute of the corresponding model inllm_model_dict, e.g..
"chatglm2-6b":"/Users/xxx/Downloads/chatglm2-6b",
- Please make sure that the local storage path of the downloaded Embedding model is written in
embedding_model_dictcorresponding to the model location, e.g.:
"m3e-base":"/Users/xxx/Downloads/m3e-base", ``` Please make sure that the local storage path of the downloaded Embedding model is written in the location of the corresponding model, e.g.
- Please make sure that the local participle path is filled in, e.g.:
text_splitter_dict = {
"ChineseRecursiveTextSplitter": {
"source": "huggingface", ## Select tiktoken to use openai's method, don't fill it in then it defaults to character length cutting method.
"tokenizer_name_or_path": "", ## Leave blank to use the big model of the tokeniser.
}
}
4. Knowledge Base Migration
The knowledge base information is stored in the database, please initialize the database before running the project (we strongly recommend one back up the knowledge files before performing operations).
-
If you migrate from
0.1.x, for the established knowledge base, please confirm that the vector library type and Embedding model of the knowledge base are consistent with the default settings inconfigs/model_config.py, if there is no change, simply add the existing repository information to the database with the following command:$ python init_database.py -
If you are a beginner of the project whose knowledge base has not been established, or the knowledge base type and embedding model in the configuration file have changed, or the previous vector library did not enable
normalize_L2, you need the following command to initialize or rebuild the knowledge base:$ python init_database.py --recreate-vs
5. Launching API Service or WebUI with One Command
5.1 Command
The script is startuppy, you can luanch all fastchat related, API,WebUI service with is, here is an example:
$ python startup.py -a
optional args including: -a(or --all-webui), --all-api, --llm-api, -c(or --controller),--openai-api, -m(or --model-worker), --api, --webui, where:
--all-webuimeans to launch all related services of WEBUI--all-apimeans to launch all related services of API--llm-apimeans to launch all related services of FastChat--openai-apimeans to launch controller and openai-api-server of FastChat onlymodel-workermeans to launch model worker of FastChat only- any other optional arg is to launch one particular function only
5.2 Launch none-default model
If you want to specify a none-default model, use --model-name arg, here is a example:
$ python startup.py --all-webui --model-name Qwen-7B-Chat
5.3 Load model with multi-gpus
If you want to load model with multi-gpus, then the following three parameters in startup.create_model_worker_app should be changed:
gpus=None,
num_gpus=1,
max_gpu_memory="20GiB"
where:
gpusis about specifying the gpus' ID, such as '0,1';num_gpusis about specifying the number of gpus to be used undergpus;max_gpu_memoryis about specifying the gpu memory of every gpu.
note:
- These parameters now can be specified by
server_config.FSCHST_MODEL_WORKERD. - In some extreme senses,
gpusdoesn't work, then one should specify the used gpus with environment variableCUDA_VISIBLE_DEVICES, here is an example:
CUDA_VISIBLE_DEVICES=0,1 python startup.py -a
5.4 Load PEFT
Including lora,p-tuning,prefix tuning, prompt tuning,ia3
This project loads the LLM service based on FastChat, so one must load the PEFT in a FastChat way. For models other than "chatglm", "falcon" or "code5p" and peft other than "p-tuning", ensure that the word peft must be in the path name, the name of the configuration file must be adapter_config.json, and the path contains PEFT weights in .bin format. The peft path is specified in args.model_names of the create_model_worker_app function in startup.py, and enable the environment variable PEFT_SHARE_BASE_WEIGHTS=true parameter.
If the above method fails, you need to start standard fastchat service step by step. Step-by-step procedure could be found Section 6. For further steps, please refer to Model invalid after loading lora fine-tuning.
5.5 Some Notes
- The
startup.pyuses multi-process mode to start the services of each module, which may cause printing order problems. Please wait for all services to be initiated before calling, and call the service according to the default or specified port (default LLM API service port:127.0.0.1:8888, default API service port:127.0.0.1:7861, default WebUI service port:127.0.0.1: 8501) - The startup time of the service differs across devices, usually it takes 3-10 minutes. If it does not start for a long time, please go to the
./logsdirectory to monitor the logs and locate the problem. - Using ctrl+C to exit on Linux may cause orphan processes due to the multi-process mechanism of Linux. You can exit through
shutdown_all.sh
5.6 Interface Examples
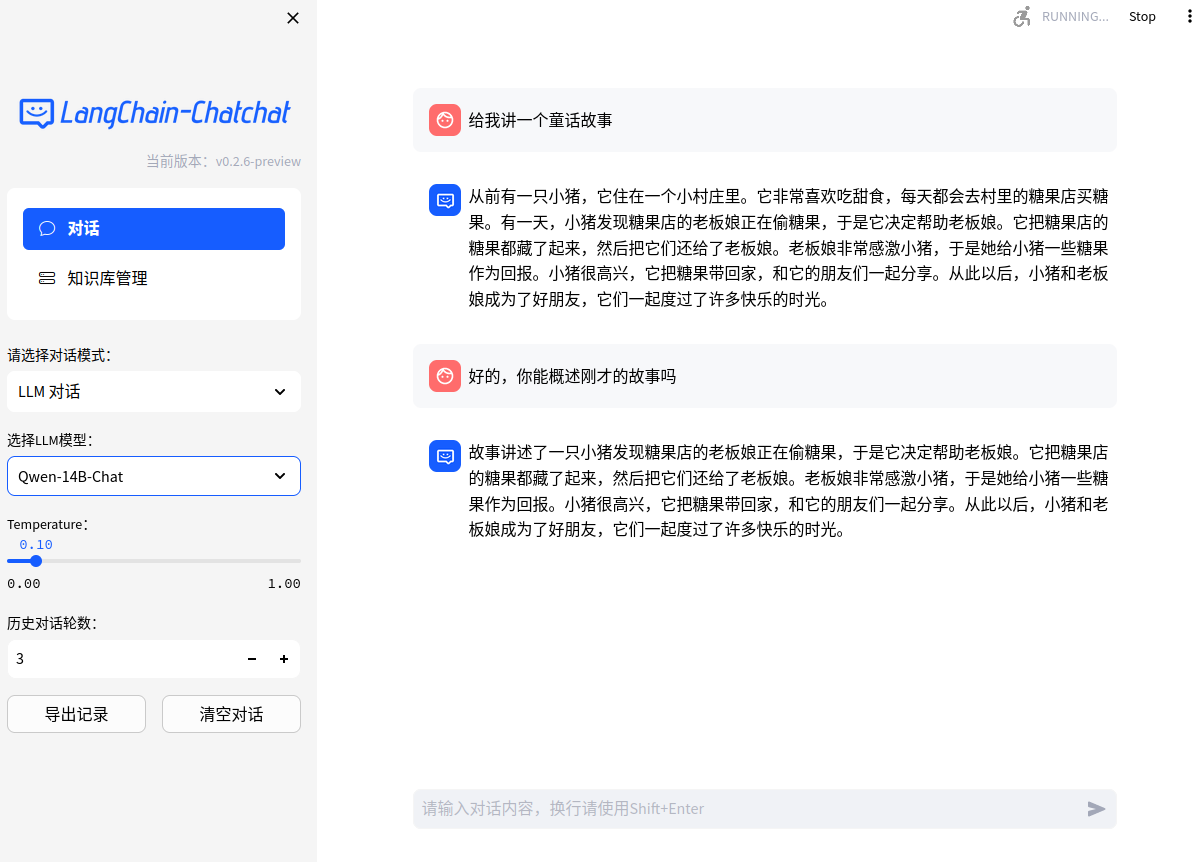
The API, chat interface of WebUI, and knowledge management interface of WebUI are list below respectively.
- FastAPI docs

- Chat Interface of WebUI
- Dialogue interface of WebUI
- Knowledge management interface of WebUI

FAQ
Please refer to FAQ
Roadmap
-
Langchain applications
-
Load local documents
-
Unstructured documents
- .md
- .txt
- .docx
-
Structured documents
- .csv
- .xlsx
-
TextSplitter and Retriever
- multiple TextSplitter
- ChineseTextSplitter
- Reconstructed Context Retriever
-
Webpage
-
SQL
-
Knowledge Database
-
-
Search Engines
- Bing
- DuckDuckGo
- Metaphor
-
Agent
- Agent implementation in the form of basic React, including calls to calculators, etc.
- Langchain's own Agent implementation and calls
- Intelligent calls to different vector databases and networking knowledge
- More tools
-
-
LLM Models
- FastChat -based LLM Models
- Mutiply Remote LLM API
-
Embedding Models
- Hugging Face-based Embedding models
- Mutiply Remote Embedding API
-
FastAPI-based API
-
Web UI
- Streamlit -based Web UI
Wechat Group

🎉 langchain-Chatchat project WeChat exchange group, if you are also interested in this project, welcome to join the group chat to participate in the discussion and exchange.
Follow us
 🎉 langchain-Chatchat project official public number, welcome to scan the code to follow.
🎉 langchain-Chatchat project official public number, welcome to scan the code to follow.