新功能:
- 支持在线 Embeddings:zhipu-api, qwen-api, minimax-api, qianfan-api
- API 增加 /other/embed_texts 接口
- init_database.py 增加 --embed-model 参数,可以指定使用的嵌入模型(本地或在线均可)
- 对于 FAISS 知识库,支持多向量库,默认位置:{KB_PATH}/vector_store/{embed_model}
- Lite 模式支持所有知识库相关功能。此模式下最主要的限制是:
- 不能使用本地 LLM 和 Embeddings 模型
- 知识库不支持 PDF 文件
- init_database.py 重建知识库时不再默认情况数据库表,增加 clear-tables 参数手动控制。
- API 和 WEBUI 中 score_threshold 参数范围改为 [0, 2],以更好的适应在线嵌入模型
问题修复:
- API 中 list_config_models 会删除 ONLINE_LLM_MODEL 中的敏感信息,导致第二轮API请求错误
开发者:
- 统一向量库的识别:以(kb_name,embed_model)为判断向量库唯一性的依据,避免 FAISS 知识库缓存加载逻辑错误
- KBServiceFactory.get_service_by_name 中添加 default_embed_model 参数,用于在构建新知识库时设置 embed_model
- 优化 kb_service 中 Embeddings 操作:
- 统一加载接口: server.utils.load_embeddings,利用全局缓存避免各处 Embeddings 传参
- 统一文本嵌入接口:server.knowledge_base.kb_service.base.[embed_texts, embed_documents]
- 重写 normalize 函数,去除对 scikit-learn/scipy 的依赖
|
||
|---|---|---|
| .github | ||
| chains | ||
| common | ||
| configs | ||
| document_loaders | ||
| embeddings | ||
| img | ||
| knowledge_base/samples | ||
| nltk_data | ||
| server | ||
| tests | ||
| text_splitter | ||
| webui_pages | ||
| .gitignore | ||
| LICENSE | ||
| README.md | ||
| README_en.md | ||
| copy_config_example.py | ||
| init_database.py | ||
| release.py | ||
| requirements.txt | ||
| requirements_api.txt | ||
| requirements_lite.txt | ||
| requirements_webui.txt | ||
| shutdown_all.sh | ||
| startup.py | ||
| webui.py | ||
README_en.md
![]()
🌍 中文文档
📃 LangChain-Chatchat (formerly Langchain-ChatGLM):
A LLM application aims to implement knowledge and search engine based QA based on Langchain and open-source or remote LLM API.
Table of Contents
Introduction
🤖️ A Q&A application based on local knowledge base implemented using the idea of langchain. The goal is to build a KBQA(Knowledge based Q&A) solution that is friendly to Chinese scenarios and open source models and can run both offline and online.
💡 Inspired by document.ai and ChatGLM-6B Pull Request , we build a local knowledge base question answering application that can be implemented using an open source model or remote LLM api throughout the process. In the latest version of this project, FastChat is used to access Vicuna, Alpaca, LLaMA, Koala, RWKV and many other models. Relying on langchain , this project supports calling services through the API provided based on FastAPI, or using the WebUI based on Streamlit.
✅ Relying on the open source LLM and Embedding models, this project can realize full-process offline private deployment. At the same time, this project also supports the call of OpenAI GPT API- and Zhipu API, and will continue to expand the access to various models and remote APIs in the future.
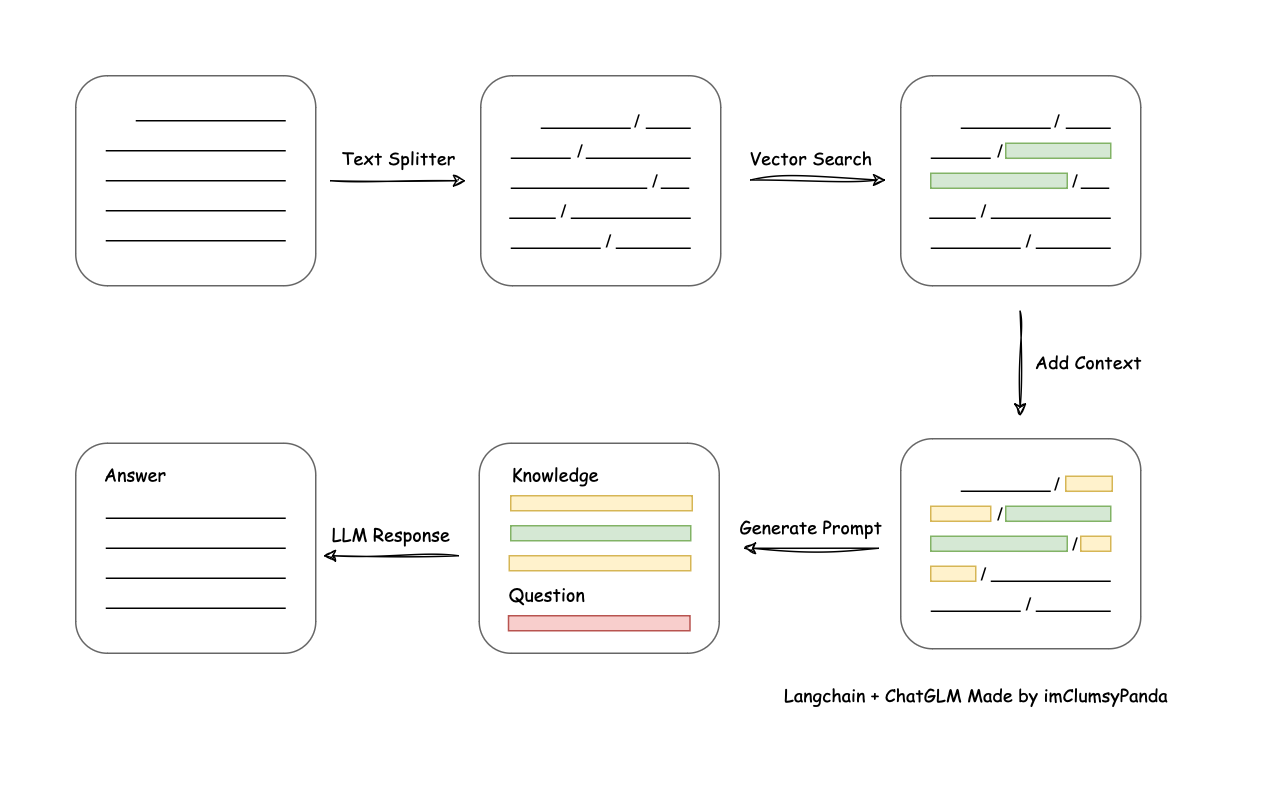
⛓️ The implementation principle of this project is shown in the graph below. The main process includes: loading files ->
reading text -> text segmentation -> text vectorization -> question vectorization -> matching the top-k most similar
to the question vector in the text vector -> The matched text is added to prompt as context and question -> submitte
to LLM to generate an answer.

The main process analysis from the aspect of document process:
🚩 The training or fine-tuning are not involved in the project, but still, one always can improve performance by do these.
🌐 AutoDL image is supported, and in v9 the codes are update to v0.2.5.
Pain Points Addressed
This project is a solution for enhancing knowledge bases with fully localized inference, specifically addressing the pain points of data security and private deployments for businesses. This open-source solution is under the Apache License and can be used for commercial purposes for free, with no fees required. We support mainstream local large prophecy models and Embedding models available in the market, as well as open-source local vector databases. For a detailed list of supported models and databases, please refer to our Wiki
Quick Start
Environment Setup
First, make sure your machine has Python 3.10 installed.
$ python --version
Python 3.10.12
Then, create a virtual environment and install the project's dependencies within the virtual environment.
# 拉取仓库
$ git clone https://github.com/chatchat-space/Langchain-Chatchat.git
# 进入目录
$ cd Langchain-Chatchat
# 安装全部依赖
$ pip install -r requirements.txt
$ pip install -r requirements_api.txt
$ pip install -r requirements_webui.txt
# 默认依赖包括基本运行环境(FAISS向量库)。如果要使用 milvus/pg_vector 等向量库,请将 requirements.txt 中相应依赖取消注释再安装。
Model Download
If you need to run this project locally or in an offline environment, you must first download the required models for the project. Typically, open-source LLM and Embedding models can be downloaded from HuggingFace.
Taking the default LLM model used in this project, THUDM/chatglm2-6b, and the Embedding model moka-ai/m3e-base as examples:
To download the models, you need to first install Git LFS and then run:
$ git lfs install
$ git clone https://huggingface.co/THUDM/chatglm2-6b
$ git clone https://huggingface.co/moka-ai/m3e-base
Initializing the Knowledge Base and Config File
Follow the steps below to initialize your own knowledge base and config file:
$ python copy_config_example.py
$ python init_database.py --recreate-vs
One-Click Launch
To start the project, run the following command:
$ python startup.py -a
Example of Launch Interface
- FastAPI docs interface

- webui page
- Web UI dialog page:
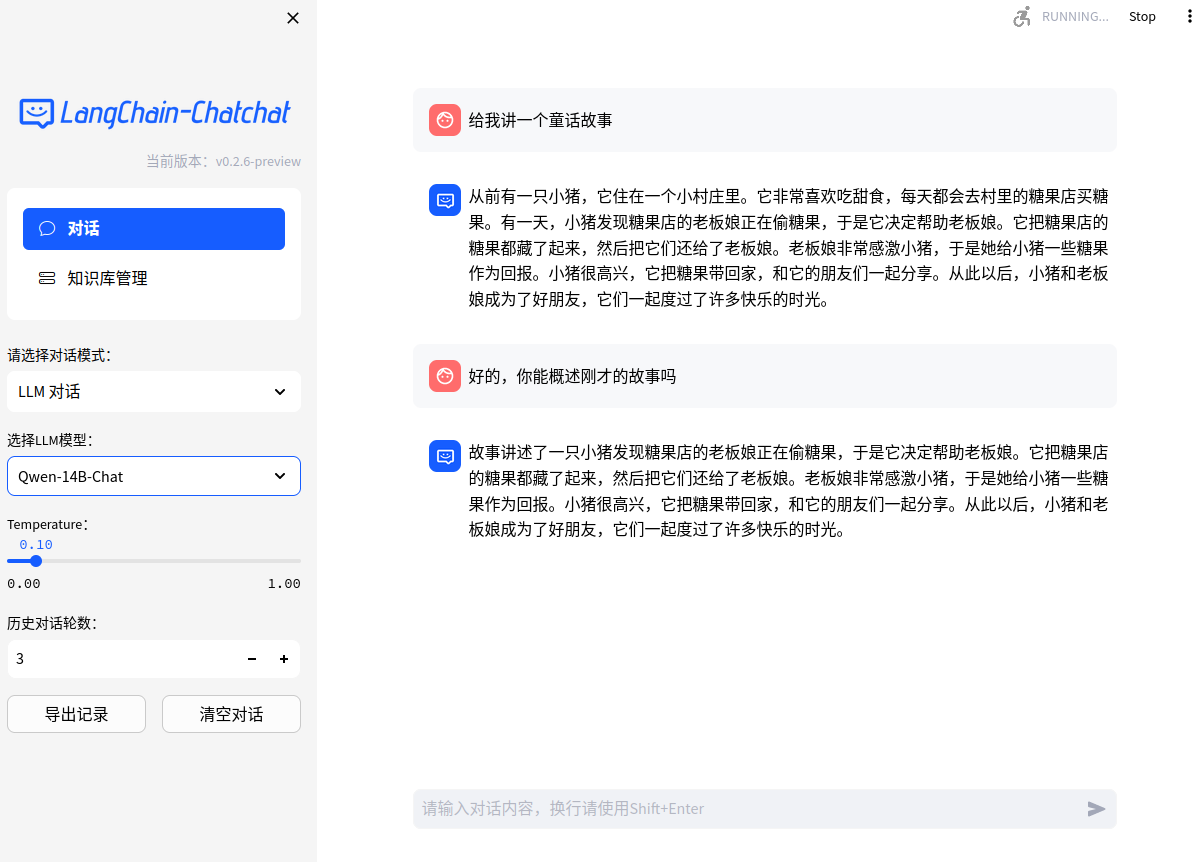
- Web UI knowledge base management page:

Note
The above instructions are provided for a quick start. If you need more features or want to customize the launch method, please refer to the Wiki.
Contact Us
Telegram
WeChat Group、

WeChat Official Account
